Definition des Risikos zu Support Vector Machines (SVM)
Wir ziehen aus einer Menge von Mustern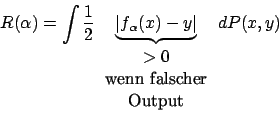
Wir können dieses Integral leider nicht berechnen. Aber wir können das impirische Risiko für
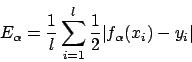
Jedoch repräsentiert
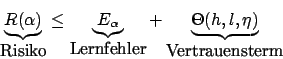
Der Vertrauensterm ist
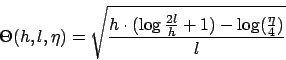
- Die Gleichung für das empirische Risiko gilt mit einer Wahrscheinlichkeit von
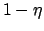 .
.
Wenn wir mit einer hohen Wahrscheinlichkeit sagen wollen, dass die Risikogleichung richtig ist, dann erhalten wir einen hohen Wert für den Vertrauesterm z.B.
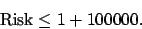
Damit können wir allerdings nichts anfangen. Wenn wir auf der anderen Seite mit einer kleinen Wahrscheinlichkeit sagen wollen, dass die Gleichung auch wirklich richtig ist, wird der Vertrauensterm klein. Das nützt aber gar nichts, weil die Gleichung dann nichts mehr aussagt. 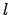 ist die Anzahl der Muster. Um den Vertrauensterm zu verkleinern können wir die Anzahl der Muster groß machen.
ist die Anzahl der Muster. Um den Vertrauensterm zu verkleinern können wir die Anzahl der Muster groß machen.
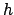 ist die VC-Dimension. Wir müssen die VC-Dimension klein machen, um den Vertrauensterm klein zu halten.
ist die VC-Dimension. Wir müssen die VC-Dimension klein machen, um den Vertrauensterm klein zu halten.