Unterabschnitte
![\includegraphics[scale=0.5]{rl-policy-valuefkt.eps}](img204.png)
Normalerweise gibt es erst am Ende des Baumes in einem Blatt einen Reward (pure delayed reward). Die Value-Function propagiert nun den Wert der Blätter in die Knoten des Baumes hoch, so dass wir für jeden Knoten (Situation) einen Wert bekommen. Teilbäume von Knoten, deren Nachfolgesituationen wir alle schon kennen, weil wir sie schon ,,erfahren'' haben, können wir abschneiden und durch den entsprechenden Wert der value function ersetzen.
Für die action value function stehen in den Knoten die Rewards für die Aktionen. Situation ist durch Aktion im obigen Text zu tauschen.
State Value Function
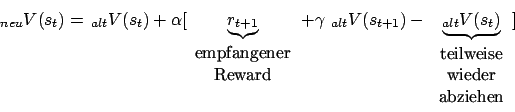
Action Value Funktion
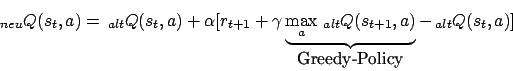
Die Action Value Function ist schneller als die State Value Function. Generell müssen wir aber im Hinterkopf behalten, dass Reinforcement Learning sehr langsam ist. Zur Zeit ist es aber wieder im Kommen, da wir immer größere Datenmengen haben.
- Was passiert?
- State Value Function
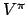
- Action Value Funktion
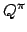
- Neuronales Netz zur Bestimmung der Value function eines Teilbaumes
Lernen der Value Function (Temporal Difference Learning)
Wir lernen die Value-Function durch Ausprobieren der Policy. Wir lernen also aus Erfahrung.
Was passiert?
Von einer Situation können wir in mehrere Unter-Situationen geraten. Von diesen Unter-Situationen können wir in weitere Unter-Situationen geraten. Wir haben einen Baum. Allerdings kann es in diesem Baum Verknüpfungen zwischen den einzelnen Ästen geben, da wir aus zwei verschiedenen Situationen in dieselbe Situation kommen können.Normalerweise gibt es erst am Ende des Baumes in einem Blatt einen Reward (pure delayed reward). Die Value-Function propagiert nun den Wert der Blätter in die Knoten des Baumes hoch, so dass wir für jeden Knoten (Situation) einen Wert bekommen. Teilbäume von Knoten, deren Nachfolgesituationen wir alle schon kennen, weil wir sie schon ,,erfahren'' haben, können wir abschneiden und durch den entsprechenden Wert der value function ersetzen.
Für die action value function stehen in den Knoten die Rewards für die Aktionen. Situation ist durch Aktion im obigen Text zu tauschen.
State Value Function
Action Value Funktion
Die Action Value Function ist schneller als die State Value Function. Generell müssen wir aber im Hinterkopf behalten, dass Reinforcement Learning sehr langsam ist. Zur Zeit ist es aber wieder im Kommen, da wir immer größere Datenmengen haben.