Unterabschnitte
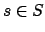 des Enviroments auf eine Aktion
des Enviroments auf eine Aktion 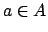 ab. Für jede Aktion bekommt der Agent einen Reward
ab. Für jede Aktion bekommt der Agent einen Reward
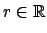 , der seine Aktion bewertet, aber nicht sagt, was er falsch gemacht hat oder was er gut gemacht hat. Beim Reinforcement Learning ist es das Ziel einen möglichst hohen Reward über eine lange Zeit zu erwirtschaften21.
, der seine Aktion bewertet, aber nicht sagt, was er falsch gemacht hat oder was er gut gemacht hat. Beim Reinforcement Learning ist es das Ziel einen möglichst hohen Reward über eine lange Zeit zu erwirtschaften21.
![\includegraphics[scale=0.5]{rl-aufbau.eps}](img188.png)
![\includegraphics[scale=0.5]{rl-situation-aktion.eps}](img189.png)
Agent lernt eine Policy
Beim Reinforcement Learning lernt der Agent eine Policy 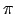 , die ihm sagt, auf welche Art und Weise er auf die jeweils aktuelle Situation reagieren soll, um an sein Ziel zu kommen.
, die ihm sagt, auf welche Art und Weise er auf die jeweils aktuelle Situation reagieren soll, um an sein Ziel zu kommen.
Es gibt zwei verschiedene Arten von Policys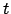 bekommt der Agent einen Reward
bekommt der Agent einen Reward 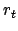 . Die Summe der zukünftigen Rewards ist der Return
. Die Summe der zukünftigen Rewards ist der Return 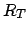
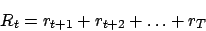
Den exakten Return können wir jedoch nicht berechnen. Wir können nur einen Erwartungswert berechnen. Dies können wir auf zwei verschiedene Art und Weise
- Agent in Environment
- Agent lernt eine Policy
- Unterschied Zustand - Situation
- Reward und Return
- Sonderfälle des Rewards
- Beispiele
Idee bzw. Aufgabe des Reinforcement Learnings (Bestärkendes Lernen)
Agent in Environment
Reinforcement Learning wird auf einen Agenten angewendet, der auf ein dynamisches Environment (System) Einfluss ausübt und in diesem Enviroment bestimmte Aufgaben ausführen muss. Der Agent bildet also die momentane Situation
Dabei kann es für ein und dieselbe Aktion in dem gleichen Zustand mehrere unterschiedliche Rewards geben. In dem Environment ist der Zufall mit enthalten.
Die Kette von Situation/Aktion kann wie folgt dargestellt werden
Agent lernt eine Policy
Beim Reinforcement Learning lernt der Agent eine Policy Es gibt zwei verschiedene Arten von Policys
- open loop policy, plan, Steuerung: Wir machen uns zu Beginn einen Plan und führen diesen bis zum Ende aus.
- closed loop policy, reactive plan, Kontrolle: Die Umgebung übt während des Ausführen des Planes Einfluss auf den Plan aus.
Unterschied Zustand - Situation
- Ein Zustand eines Systems ist die Abspeicherung aller Variablen, die das System hat. Aus diesen Variablen läßt sich der Zustand komplett rekonstruieren. Ist es möglich Zustände eines Systems in jedem Schritt zu bekommen, so können wir die Policy mit Marcow Decision Problems (MDPs) komplett berechnen (im Prinzip).
- Bei den meisten Systemen kommen wir jedoch an alle Variablen gar nicht dran, weshalb die unvollständige Variablemenge nur eine Situation ist.
Reward und Return
Für eine Aktion zum ZeitpunktDen exakten Return können wir jedoch nicht berechnen. Wir können nur einen Erwartungswert berechnen. Dies können wir auf zwei verschiedene Art und Weise
- Wir können die Aktionen zeitlich unterteilen in Trials, Episodes. Wir können den Erwartungswert des Returns einer Episode ermitteln.
Wenn die Episode unendlich lang ist, dann hat dies keinen Sinn, da der Return unendlich wird. - Wir können ein discounting einführen, um mit delayed rewards, zu denen wir nicht wissen, wann diese genau auftauchen, umzugehen. Wir gewichten in ferner Zukunft liegende Rewards weniger, als Rewards, die wir schnell erhalten. Wir wählen ein
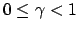 und
und  und berechnen diesen Reward wie folgt
und berechnen diesen Reward wie folgt
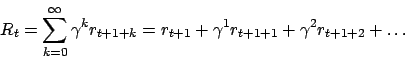
Sonderfälle des Rewards
- Pure delayed reward: Ganz lange Zeit bleibt der Reward
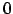 . Erst am Ziel wird ein positiver oder negativer Reward gegeben. Kann zum Beispiel ein Spiel sein, wo erst am Ende dann feststeht, wer gewonnen hat.
. Erst am Ziel wird ein positiver oder negativer Reward gegeben. Kann zum Beispiel ein Spiel sein, wo erst am Ende dann feststeht, wer gewonnen hat.
- Jede Aktion kostet: Jedes Mal, wenn der Agent eine Aktion macht, wird er bestraft:
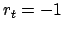 . Erst wenn der Agent am Ziel ankommt, wird er belohnt. Wenn nun zusätzlich in jedem Zeitschritt eine Aktion erzwungen wird, wird der Agent versuchen mit möglichst wenig Schritten am Ziel anzukommen.
. Erst wenn der Agent am Ziel ankommt, wird er belohnt. Wenn nun zusätzlich in jedem Zeitschritt eine Aktion erzwungen wird, wird der Agent versuchen mit möglichst wenig Schritten am Ziel anzukommen.
- Pure negative reward: Es wird immer ein Reward gegeben. Nur wenn der Agent etwas schlechtes macht, bzw. in einer schlechten Situation ist, gibt es einen negativen Reward.
Beispiele
- TD-Gammon: Reinforcementlearning zum Spielen von Backgammon. Anwendung von Pure delayed reward.
- Auto in Senke: Ein Auto befindet sich in einer Senke. Unser Ziel ist es, dass es aus der Senke herauskommt. Das Auto hat zu wenig Motorleistung um mit einem Anlauf aus der Senke herauszufahren. Wir bestrafen aber das Auto immer, wenn es sich in der Senke befindet. Erst am Ziel setzen wir den Reward auf :
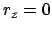 . (2.Sonderfall) Dieses System wird sich langsam hochschaukeln.
. (2.Sonderfall) Dieses System wird sich langsam hochschaukeln.
- Pole Balancer:
Der Polebalancer besteht aus
![\includegraphics[scale=0.75]{polebalancer.eps}](img199.png)
- einem Wagen, der nach links und rechts per Bang-Bang-Control beschleunigt werden kann. Dabei muss er immer in eine Richtung beschleunigt werden. Er kann nicht einfach stehen gelassen werden.
- Der Wagen hat eine Position
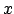 auf der Schiene mit einer Geschwindigkeit
auf der Schiene mit einer Geschwindigkeit 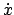 .
.
- An den Seiten der Schiene, auf der der Wagen steht, befinden sich Begrenzungen.
- Auf dem Wagen befindet sich ein Pole an einem Gelenk. Dieser hat einen Winkel
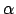 zur Senkrechten und eine Geschwindigkeit
zur Senkrechten und eine Geschwindigkeit 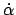 .
.